YOLOv4: Optimal Speed and Accuracy of Object Detection
Alexey Bochkovskiy, Chien-Yao Wang, Hong-Yuan Mark Liao
上篇主要說明YOLOv4的重點Bag of freebies以及Bag of specials。
~台灣之光~
-
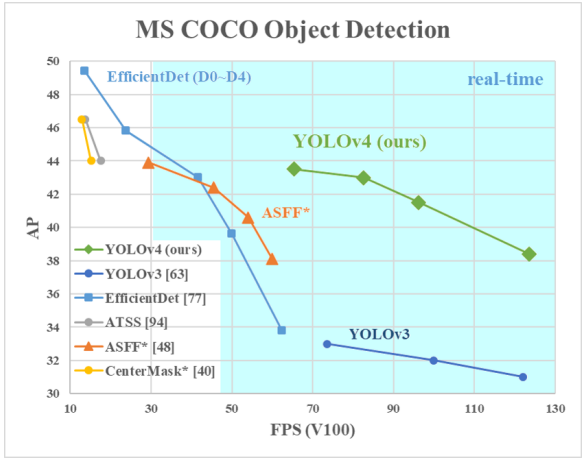
在傳統GPU上進行realtime處理,並只須用一顆GPU進行訓練。
-
CBN、PAN、SAM技術使模型更適合在單顆GPU上更有效的訓練
-
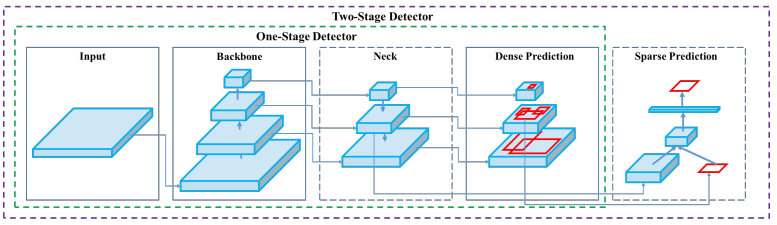
物件偵測模型分成: Backbone、Neck以及Head.
-
Backbones: 特徵提取,通常用ImageNet預訓練。
-
Neck: 蒐集不同階段的特徵圖。
-
Head: 用來預測類別以及物件的Bounding Boxes。
問題
- 某些特徵操作只適用於特定的網路模型,或是只適用於小型資料集。
- 高準確度的模型通常無法達到realtime,且需要用很多顆GPU並用很大的Batch進行訓練。
方法
Bag of Freebies
-
只增加訓練花費,但是不會增加推論時的花費。
-
資料增強技術(Data augmentation),使模型更加robust。(論文中有很多augmentation技術介紹,有興趣者可以參閱原文)
-
資料不平衡的解決辦法:
- example mining: 不適用一階段偵測的模型。
- focal loss
-
Label smoothing:將hard label轉成soft label使模型更加robust。
-
Bounding Box回歸(regression):
- 過去用Mean Square Error求Bounding Box的中心點座標以及長寬,但是每個值對MSE來說是獨立的,沒有考量到物件的整體。
- 因此有IoU的提出,解決上述問題。
- IoU的改進:
-
G-IoU: 考慮到了預測框與正確框的重合度(公式C為兩框的最小矩形面積)
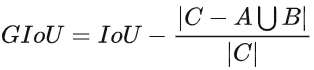
-
D-IoU: 考慮了物件的中心點之間的距離。
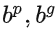 分別為預測框與正確框。
分別為預測框與正確框。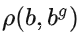 代表兩框間中心點的歐式距離,C代表兩框最小外接矩形的對角線距離。
代表兩框間中心點的歐式距離,C代表兩框最小外接矩形的對角線距離。
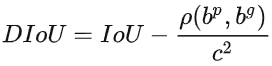
-
C-IoU: 在D-IoU的基礎下還考慮了長寬比。
V為長寬比一致性,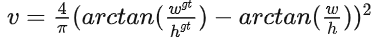 ,
,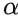 為調節參數,
為調節參數,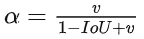 。
。
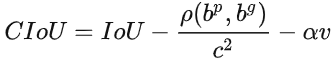
Bag of Specials
-
增加一點點的推論時間但是能提升準確度很多。
-
增加感受野:
-
SPP : Spatial Pyramid Pooling,任意大小的輸入特徵圖都可以輸出一維的特徵向量。但能應用在全連接卷積網路當中,因此本文將不同尺度的Max-pooling輸出特徵圖concated起來,以此增加網路的感受野(recpetive field)。
-
ASPP : Atrous spatial pyramid pooling,想要有大感受野,就要採用大的卷積核或採用較大步長(stride)的pooling,但是計算量會比較大,因此採用空洞卷積方式。
-
RFB : Reception field block,CNN與ASPP的結合,因為會經過不同rate的空洞卷積後再進行concate以及1×1卷積,因此物件的重點會在於卷積核中心位置。
-
注意力機制(Attention Module):
-
可分成Channel-wise以及Point-wise。
-
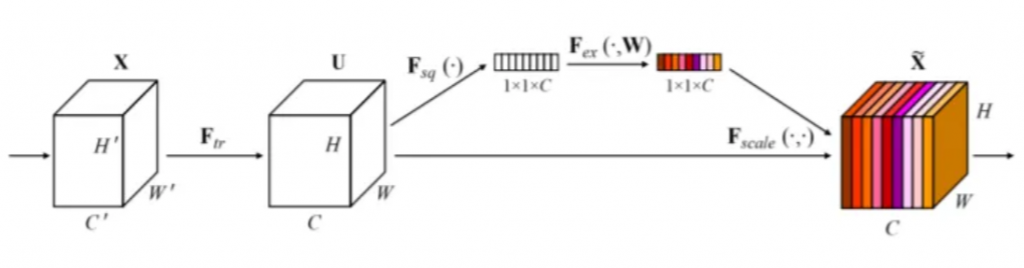
SE: Squeeze-and-Excitation,學習通道間的關聯性,影像先經過卷積後得到的特徵圖,並經過Squeeze後得到與通道數一樣的向量,再經過Excitation得到重要的影像資訊,最後將一維向量資訊Rescale回原圖一樣大小。
-
Squeeze: 進行global average pooling進行特徵壓縮,使每一個channel都有全域的資訊。
-
Exciatation: 利用非線性激活函數來學習重要影像資訊。
-
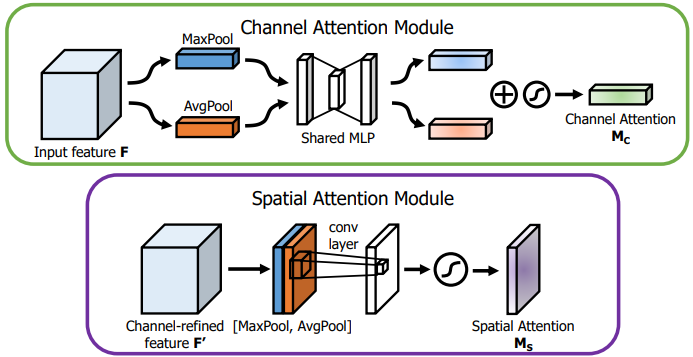
CBAM: Convolutional block attention module,先進行Channel再進行Spatial attention。
-
Channel Attention: 通過Max Pooling及average Pooling,分別輸入到MLP當中並輸出各自的一維向量,最後將兩輸出by pixel進行合併。
-
Spatial Attention: 同樣進行Max Pooling以及Average Pooling,並將兩輸出特徵圖concated在一起,再經過一個卷積運算後得到一張與原圖大小相同的特徵圖。
-
作者實驗SE在GPU運行可提升10%推論速度,SAM在GPU運行也不會影響推論速度。
-
特徵融合:
-
將低階物理特徵與高階語意資訊融合在一起。
-
FPN(Feature Pyramid Network)
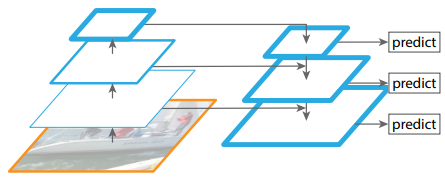
-
SFAM(Single-Shot Multi-Level Feature Paramid Network):
- 利用不同尺度下進行SE運算並將輸出的特徵圖Concated起來。
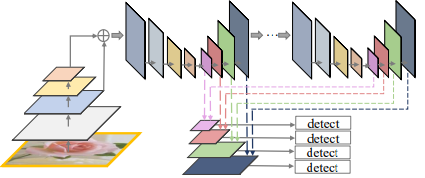
-
ASFF(Adaptively spatial feature fusion):
- 作者認為過去採用concated以及element-wise方式進行特徵融合並不能很好的利用不同尺度的特徵,因此採用不同層的特徵乘上不同尺度對應的權重,再進行相加得到融合後的特徵圖。
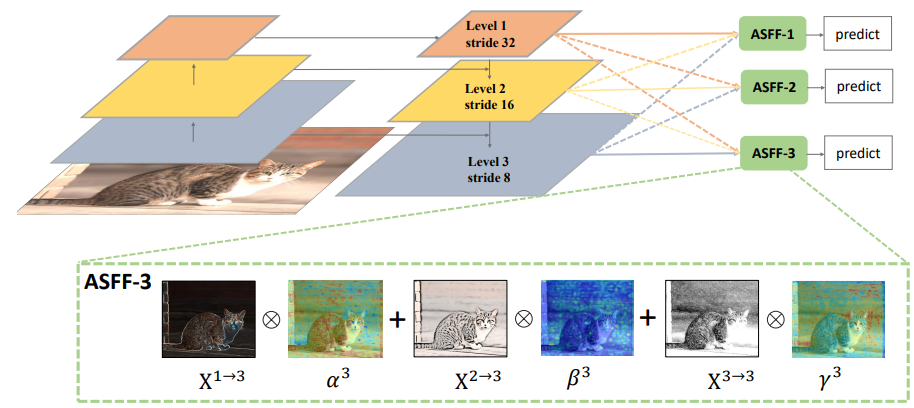
-
BiFPN(Biderectional Feature Paramid Network):
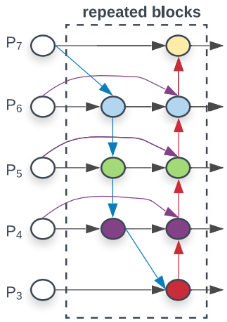
-
激活函數:
- 讓模型進行權重倒傳遞更加有效率,且不會增加運算成本。
-
ReLU: 解決Sigmoid以及tanh特徵消失的問題。
-
LRELU、PReLU: 解決輸出小於0時,ReLu梯度為0的問題。
-
ReLu6: 設計用來處理量化(quantization)網路。
-
SELU: 用來處理self-normalizing 神經網路。
-
Swish、Mish: 連續可微分的激活函數。
-
後處理:
-
NMS: Non-Maximum Suppression,用來過濾掉同一物件重複的預測框。
-
Greedy NMS: 引入信心度值。
-
DIoU-NMS:引入Bounding Box的中心點距離資訊。
文章使用之圖片擷取自該篇論文
其他提升準確度方法以及YOLOv4架構及實驗結果將於YOLOv4-下篇進行說明。


 iThome鐵人賽
iThome鐵人賽